[Spring Batch] chunk transaction 동작 과정
안녕하세요 오늘은 spring batch에 chunk에 대해서 자세히 알아보려고 합니다. spring batch를 진행하면서 대용량의 데이터를 처리를 고민해야 하는 경우가 많은데요.
그럴때마다 떠오르는 것이 chunk 입니다. 해당 chunk는 어디에 영향을 끼치지고 어떤걸 의미 하는걸까? 해당 의미를 정확히 모르고 사용하는 경우가 많고 저 또한 잘 모르고 사용한 적이 있던 거 같아 이렇게 정리 할 겸 남기게 되었습니다.
chunk란?
데이터 처리의 단위를 의미하며, "한 번에 읽고, 처리하고, 쓸 데이터의 묶음" 이라고 정의할 수 있고 Spring Batch에서 ItemReader → ItemProcessor → ItemWriter가 하나의 트랜잭션 내에서 처리하는 아이템의 묶음이라고 보시면 됩니다.
쉽게 말해 chunk는 많은양의 데이터를 한번에 한번에 저장하는게 아니라 작은 단위의 트랜잭션으로 나누어서 동작한다고 생각 하시면 됩니다.
그러면 chunk 방식으로 왜 처리 할까? 하고 궁금해 하실 수 있는데 아래와 같다고 생각합니다.
- 한 번에 대용량 데이터를 처리하는 건 부하를 많이 주지만 나누어 처리하면 성능적으로 효율적입니다.
- 작은 단위로 commit 하여 실패 시 롤백에 용이하여 다시 처음부터 시작 하지 않고 실패 한 시점 부터 재 실행 가능합니다.
- 전체 데이터를 메모리에 다 올리지 않고 처리가 가능합니다.
- 병렬 처리 작업에 chunk 단위에 병렬성 확보가 가능합니다.
처음 단순히 chunk size가 영향을 주는게 writer 라고 생각 하기 쉽습니다. 보통 트랜잭션을 생각해보면 rollback을 먼저 떠 올리신 텐데 그렇기 때문에 chunk size는 = writer item의 단위 로 생각하기 쉬운데 그것은 아닙니다!
chunk size는 쉽게 생각하면 reader에 영향을 준다고 생각 하시면 쉽습니다.
보통 chunk로 진행을 할떄 reader로 대표적으로 아래를 Reader를 많이 사용하실 거 같은데요.
- JdbcPagingItemReader
- JdbcCursorItemReader
- JpaPagingItemReader
그중 예로 JdbcPagingItemReader 설정을 할때 아래와 같이 설정을 많이 하실 거 같습니다.
private final CHUNK_SIZE = 100;
new JdbcPagingItemReaderBuilder<Test>()
.name("jdbcPagingItemReader")
.pageSize(CHUNK_SIZE)
.dataSource(dataSource)
.rowMapper(new BeanPropertyRowMapper<>(Test.class))
.queryProvider(queryProvider())
.parameterValues(parameterValue)
.build();
pageSize=ChunkSize 형태로 많이들 설정을 하는데 위의 동작은 db로부터 select DML로 page size인 100개씩 데이터를 가져오게 됩니다. 그리고 ItemReader → ItemProcessor → ItemWriter 순서로 처리를 하게 되는 과정으로 다 알고 계시는 내용일 겁니다.
여기서 만약 processor에서 개수를 변경하면 어떻게 될까요?
물론 올바른 방식은 아니지만 그렇게 처리 해야한다면 이경우 chunk는 어떻게 되는걸까? 고민하신적 있을까요?
그래서 아래와 같은 flow로 진행해서 테스트 해보려고 합니다
- 총 데이터의 개수는 5개가 존재한다.
- reader 에서는 chunk size는 3으로 설정하여 3개씩 select 하여 데이터를 가지고 온다.
- processor 에서는 item 당 2개의 list로 변환하여 넘긴다.
- wrtier 에서는 받은 데이터를 저장한다.
reader/processor/writer 의 구성은 아래와 같습니다.
reader
- 5개의 list를 구성하고 하나씩 가져가는 reader
@Bean
public ItemReader<String> reader() {
List<String> items = List.of("one", "two", "three", "four", "five");
Iterator<String> iterator = items.iterator();
return () -> {
if (iterator.hasNext()) {
String item = iterator.next();
System.out.println("[Pooney Reader] Read item: " + item);
return item;
}
return null;
};}
processor
- item 하나당 2개의 list로 반환하는 processor
@Bean
public ItemProcessor<String, List<String>> processor() {
return item -> {
List<String> processed = new ArrayList<>();
processed.add(item);
processed.add(item + "_copy");
System.out.println("Pooney Processor] Processed item: " + processed);
return processed;
};}
writer
- 전달 받은 list에 대한 카운팅과 로그 출력
@Bean
public ItemWriter<List<String>> writer() {
return items -> {
List<String> flat = items.stream().flatMap(List::stream).toList();
Tracker.writeCount += flat.size();
System.out.println("[Pooney Writer] Writing chunk with items: " + flat);
};}
@Configuration
@RequiredArgsConstructor
public class ChunkJob {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
private final DataSource dataSource;
@Bean
public Job chunkTestJob() {
return jobBuilderFactory.get("chunkTestJob1")
.incrementer(new RunIdIncrementer())
.start(chunkTestStep())
.build();
}
@Bean
public Step chunkTestStep() {
return stepBuilderFactory.get("chunkTestStep")
.<String, List<String>>chunk(3)
.reader(reader())
.processor(processor())
.writer(writer())
.build();
}
@Bean
public ItemReader<String> reader() {
List<String> items = List.of("one", "two", "three", "four", "five");
Iterator<String> iterator = items.iterator();
return () -> {
if (iterator.hasNext()) {
String item = iterator.next();
System.out.println("[Reader] Read item: " + item);
return item;
}
return null;
}; }
@Bean
public ItemProcessor<String, List<String>> processor() {
return item -> {
List<String> processed = new ArrayList<>();
processed.add(item);
processed.add(item + "_copy");
System.out.println("[Processor] Processed item: " + processed);
return processed;
}; }
@Bean
public ItemWriter<List<String>> writer() {
return items -> {
List<String> flat = items.stream().flatMap(List::stream).toList();
System.out.println("[Writer] Writing chunk with items: " + flat);
}; }
}
배치를 실행해 보고 1번 로그 결과를 확인 해보면 아래와 같은데요.
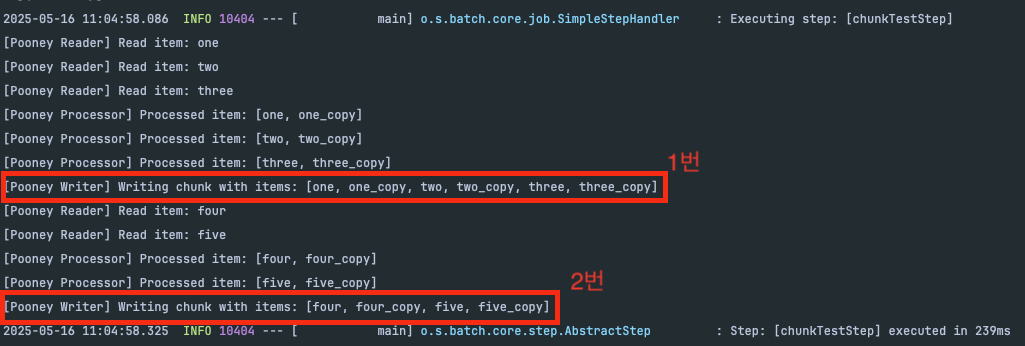
reader에서는 chunk size 3개씩 데이터를 읽지만, writer에서는 chunk size가 아닌 6개가 write 되는것을 확인 할 수 있습니다. 또한 2번로그는 reader에서 2개를 읽고 > processor에서 4개 > writer 4개 write 되는 것을 볼 수 있습니다.
그러면 왜 이렇게 동작하는지 궁금 하실 수 있는데요? 이유는 step이 시작할떄 하나의 트랜잭션으로 동작 하기 떄문입니다.
즉 step이 시작할때 트랜잭션을 시작을 하면서 db connection pool에서 connection 하나를 자기고 오고 해당 connection은 ThreadLocal에 저장합니다. 이후 reader는 ThreadLocal에 저장된 connection을 가지고 쿼리를 요청하고, writer도 동일하게 해당 커넥션을 가지고 쿼리를 요청 후 작업 완료가 되면 commit을 하고 반납하는 구조로 구성되어 있고 chunk단위로 반복 수행 하게 됩니다.
즉 chunk 단위로 트랜잭션 , connection이 바뀐다고 보시면 됩니다.
그럼 이러한 connection의 변화를 확인 하기 위해 아래와 같이 코드를 추가하여 확인 해 보겠습니다.
ConnectionTracker
- 커넥션을 추적하기 위한 component
@Component
public class ConnectionTracker {
public static Connection readerConnection;
public static Connection writerConnection;
}
@Configuration
@RequiredArgsConstructor
public class ChunkJob {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
private final DataSource dataSource;
@Bean
public Job chunkTestJob() {
return jobBuilderFactory.get("chunkTestJob1")
.incrementer(new RunIdIncrementer())
.start(chunkTestStep())
.build();
}
@Bean
public Step chunkTestStep() {
return stepBuilderFactory.get("chunkTestStep")
.<String, List<String>>chunk(3)
.reader(reader())
.processor(processor())
.writer(writer())
.build();
}
@Bean
public ItemReader<String> reader() {
List<String> items = List.of("one", "two", "three", "four", "five");
Iterator<String> iterator = items.iterator();
return () -> {
if (iterator.hasNext()) {
Connection conn = DataSourceUtils.getConnection(dataSource);
ConnectionTracker.readerConnection = conn;
System.out.println("[Reader] Connection: " + conn);
String item = iterator.next();
System.out.println("[Reader] Read item: " + item);
return item;
}
return null;
}; }
@Bean
public ItemProcessor<String, List<String>> processor() {
return item -> {
// item마다 1개씩 추가
List<String> processed = new ArrayList<>();
processed.add(item);
processed.add(item + "_copy");
System.out.println("[Processor] Processed item: " + processed);
return processed;
}; }
@Bean
public ItemWriter<List<String>> writer() {
return items -> {
// items는 List<List<String>> Connection conn = DataSourceUtils.getConnection(dataSource);
ConnectionTracker.writerConnection = conn;
System.out.println("[Writer] Connection: " + conn);
if (ConnectionTracker.readerConnection == conn) {
System.out.println("Same connection used!");
} else {
System.out.println("Different connections used!");
}
List<String> flat = items.stream().flatMap(List::stream).toList();
System.out.println("[Writer] Writing chunk with items: " + flat);
}; }
}
배치를 한번 실행해고 결과는 아래와 같습니다.

보시면 reader ,writer 에서 Same connection used! 로그로 동일한 connection을 사용하는 것을 확인 할 수 있습니다. 결국 동일 connection을 사용하기 때문에 하나의 트랜잭션으로 reader에서 부터 writer까지 하나의 묶음으로 진행이 되는 것을 확인 할 수 있습니다.
좀더 보기 쉽게 그림으로 정리를 해봤습니다.

위 그림처럼 흐름으로 chunk 단위의 작업이 이루어지 진다고 보시면 됩니다. 최대한 이해하기 쉽게 하긴 했는데, 그로인해 부족한 점이 있긴 하지만 이해해주시면 감사하겠습니다.
대용량의 배치를 처리하면서 트랜잭션, chunk가 중요했는데요. 그러면서 `어떻게 chunk 작업을 진행할까? chunk의 범위는 어디까지 일까?` 등 배치가 처리하 방법을 알면 좀더 안정적으로 배치를 구성 할 수 있겠다 싶어서 공부를 하게 되었는데 많은 도움이 되었던거 같습니다.